Click here to expand...
Hypothesis Test 1-Tailed & 2-Tailed are dual to Confidence Interval - 1-Tailed & 2-Tailed
- Two-Sided Hypothesis - 𝐻0: 𝜃 = 𝜃0 against 𝐻𝑎: 𝜃 ≠ 𝜃0
- One-Sided, Right-Tailed - 𝐻0: (𝜃 = 𝜃0) or (𝜃 ≤ 𝜃0) against 𝐻𝑎: 𝜃 > 𝜃0
- One-Sided, Left-Tailed - 𝐻0: (𝜃 = 𝜃0) or (𝜃 ≥ 𝜃0) against 𝐻𝑎: 𝜃 < 𝜃0
pick the null hypothesis (𝐻0) and alternative hypotheses (𝐻𝑎) based on your goals. For example:
- two-tail hypothesis:
- 𝐻0 : Average Grade = 80%
- 𝐻𝑎 : Average Grade ≠ 80%
- one-tail (right-tail) hypothesis:
- 𝐻0 : Average Grade = 80%
- 𝐻𝑎 : Average Grade > 80%
- one-tail (left-tail) hypothesis:
- 𝐻0 : Average Grade = 80%
- 𝐻𝑎 : Average Grade < 80%
When you conduct a test of statistical significance (e.g. correlation, analysis of variance (ANOVA), regression, etc) you are given a p-value somewhere in the output
If your test statistic is symmetrically distributed, you can select 1 of 3 alternative hypotheses:
- 1 corresponds to a two-tailed test
- 2 of these correspond to one-tailed tests
The p-value presented is (almost always) for a two-tailed test.
- but how do you choose which test?
- is the p-value appropriate for your test?
- and, if it is not, how can you calculate the correct p-value for your test given the p-value in your output?
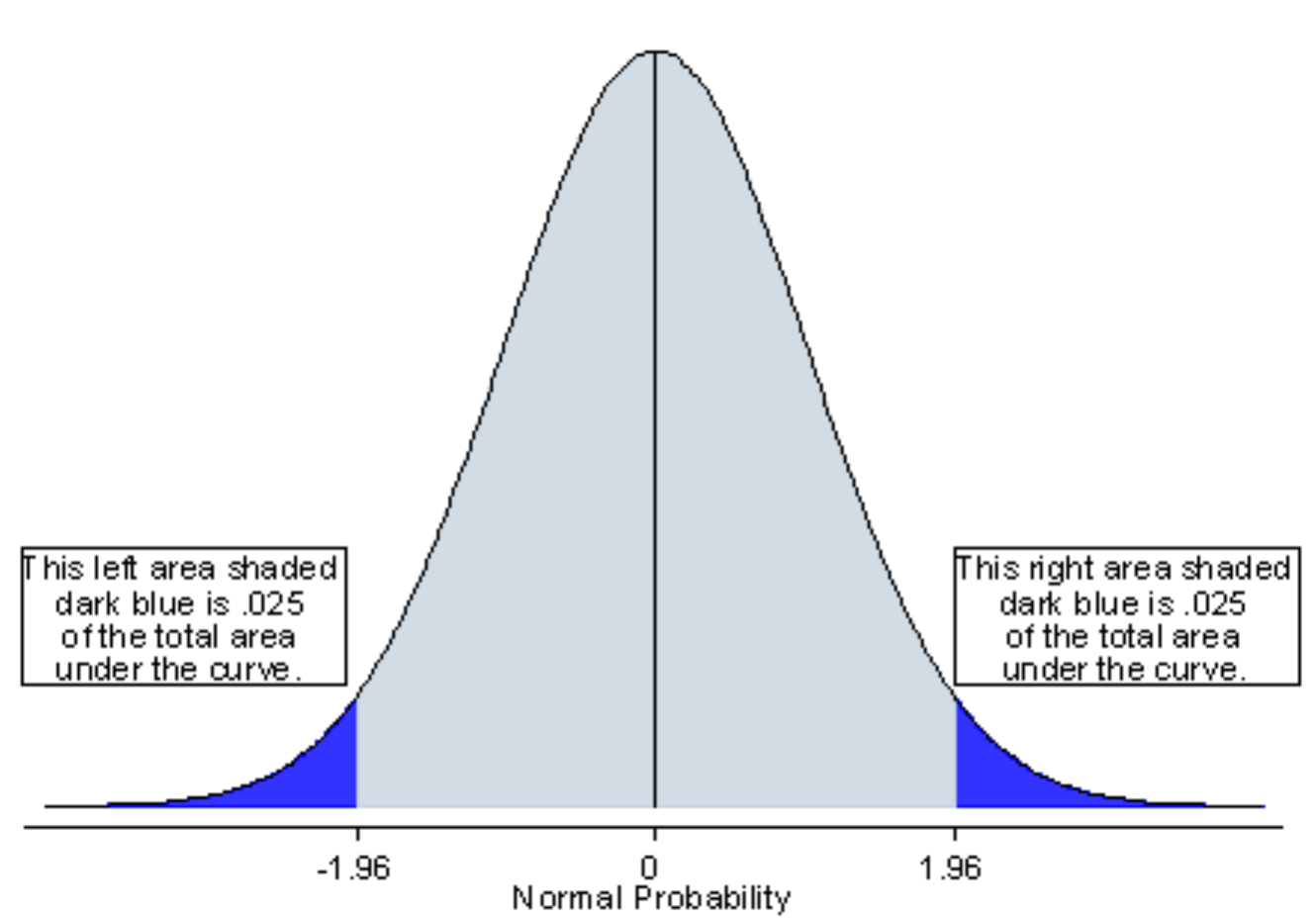
2-Tailed Test
If you are using a significance level of 𝛼=0.05, a two-tailed test allots:
- HALF of your 𝛼 to testing the statistical significance in one direction
- HALF of your 𝛼 to testing the statistical significance in the other direction
This means that .025 is in each tail of the distribution of your test statistic.
For Example
- we may wish to compare the mean of a sample to a given value x using a t-test
- our null hypothesis is that the mean is equal to x
- a two-tailed test will test BOTH:
- if the mean is significantly greater than x
- if the mean is significantly less than x
- the mean is considered significantly different from x if the test statistic is in the top 2.5% or bottom 2.5% of its probability distribution, resulting in a p-value less than 0.05
- we reject the null-hypothesis if the p-value is less than 0.05
two-tailed hypothesis test / two-tailed CI
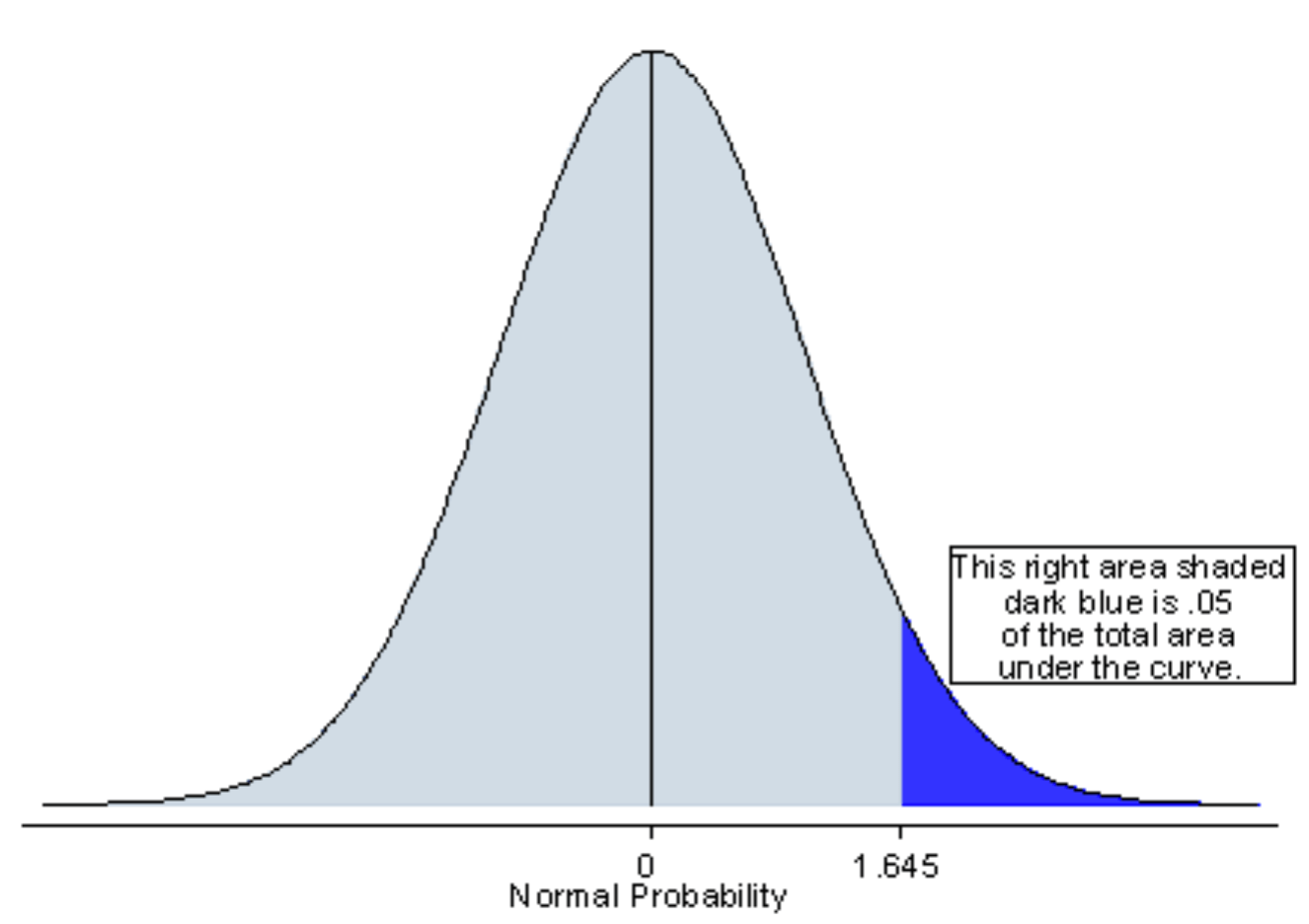
1-Tailed Test
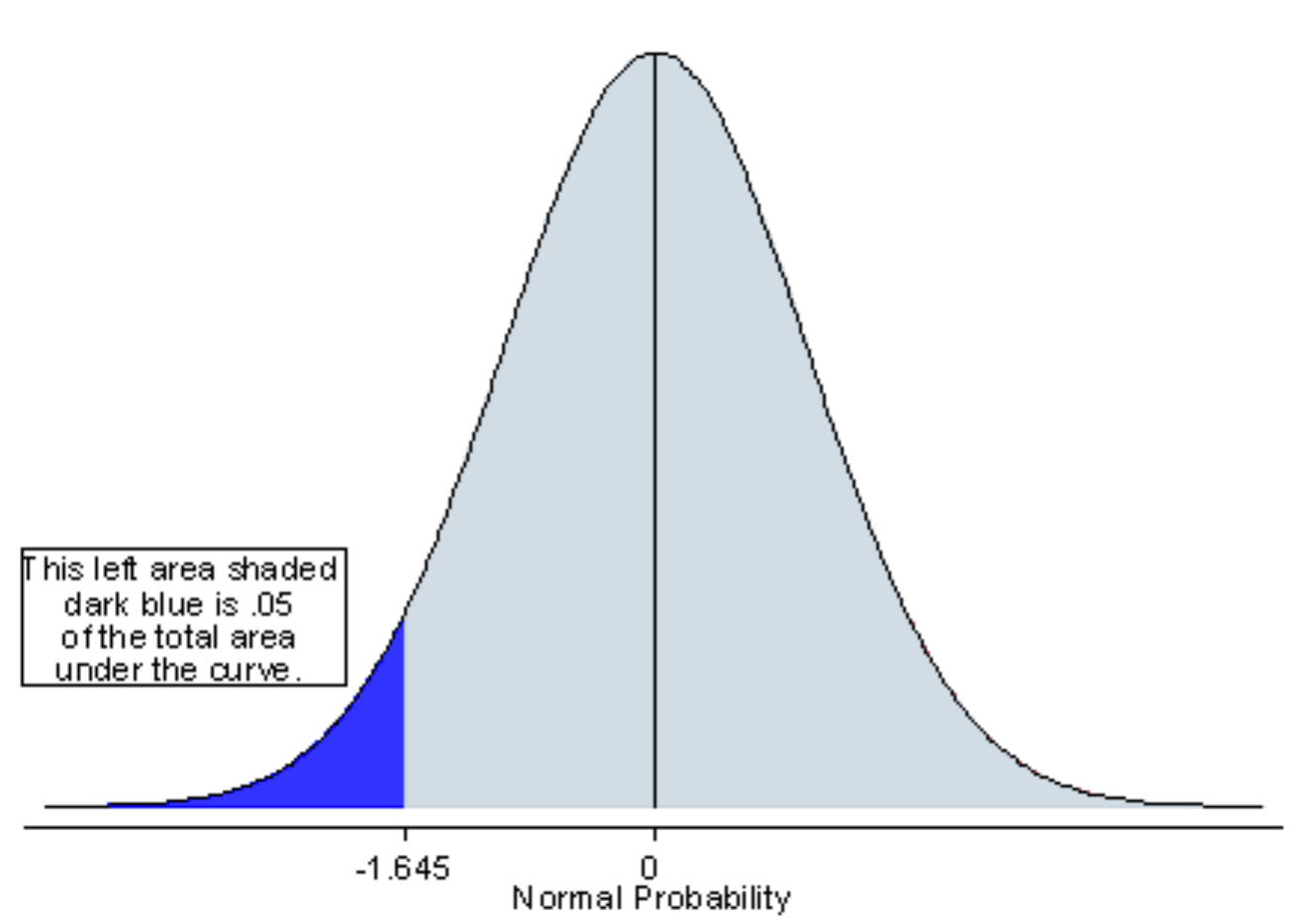
If you are using a significance level of 𝛼=0.05, a one-tailed test allots:
- ALL of your 𝛼 to testing the statistical significance in the one direction of interest
This means that 0.05 is in one tail of the distribution of your test statistic.
For Example
- let’s return to our example comparing the mean of a sample to a given value x using a t-test
- our null hypothesis is that the mean is equal to x
- a one-tailed test will test EITHER (not both):
- the mean is significantly greater than or less than x if the test statistic is in the top 5% of its probability distribution or bottom 5% of its probability distribution, resulting in a p-value less than 0.05
- we reject the null-hypothesis if the p-value is less than 0.05
(upper/right)-tailed hypothesis test / lower CI?
(lower/left)-tailed hypothesis test / upper CI?
When is a 1-Tailed Test Appropriate?
Because the one-tailed test provides more power to detect an effect, you may be tempted to use a one-tailed test whenever you have a hypothesis about the direction of an effect. Before doing so, consider the consequences of missing an effect in the other direction. Imagine you have developed a new drug that you believe is an improvement over an existing drug. You wish to maximize your ability to detect the improvement, so you opt for a one-tailed test. In doing so, you fail to test for the possibility that the new drug is less effective than the existing drug. The consequences in this example are extreme, but they illustrate a danger of inappropriate use of a one-tailed test.
So when is a one-tailed test appropriate? If you consider the consequences of missing an effect in the untested direction and conclude that they are negligible and in no way irresponsible or unethical, then you can proceed with a one-tailed test. For example, imagine again that you have developed a new drug. It is cheaper than the existing drug and, you believe, no less effective. In testing this drug, you are only interested in testing if it less effective than the existing drug. You do not care if it is significantly more effective. You only wish to show that it is not less effective. In this scenario, a one-tailed test would be appropriate.
When is a 1-Tailed Test NOT Appropriate?
Choosing a one-tailed test for the sole purpose of attaining significance is not appropriate. Choosing a one-tailed test after running a two-tailed test that failed to reject the null hypothesis is not appropriate, no matter how “close” to significant the two-tailed test was. Using statistical tests inappropriately can lead to invalid results that are not replicable and highly questionable–a steep price to pay for a significance star in your results table!